老网站
6.2 CPU1队列提交作业
CPU1队列使用Slurm作业调度系统管理所有计算作业,该系统接受用户的作业请求,并将作业合理的分配到合适的节点上运行。下图为用户提交作业的示意图:
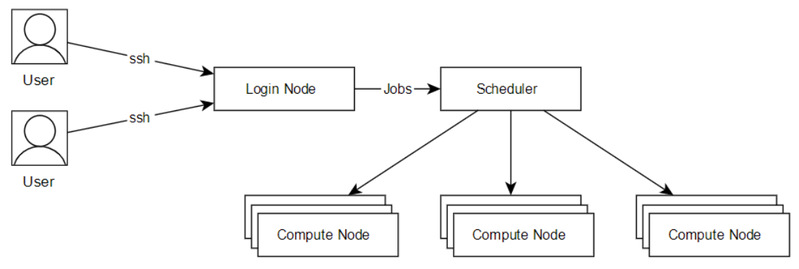
图1 提交作业示意图
本节将介绍运行作业的两种方式,一种是将计算过程写成脚本,通过sbatch指令提交到计算节点执行,另一种是通过salloc申请到计算节点,再ssh连接到计算节点进行计算本节还将介绍如何sinfo、squeue、scancel等命令具体操作。
1)sbatch提交作业
注意:本文命令中所有“cpu”均代表CPU1队列,“gpu4”“gpu8”代表GPU节点的4卡和8卡GPU队列。
用户使用sbatch命令向作业调度系统提交作业,sbatch可用参数十分丰富,可对作业进行非常细致的控制,这里简要介绍常用参数和方法。
运行作业的第一种方式是将整个计算过程,写到脚本中,通过sbatch指令提交到计算节点上执行。先介绍一个简单的例子,假设我们的计算过程为,在计算节点上运行hostname指令,那么就可以如下编写作业脚本:
#!/bin/bash
#!/bin/bash
#SBATCH -J test
#SBATCH -p cpu
#SBATCH -n 64
#SBATCH --error=%J.err
#SBATCH --output=%J.out
hostname
假设上面作业脚本的文件名为job.sh,通过以下命令提交:
sbatch job.sh
随后我们介绍脚本中涉及的参数:
-J test # 作业在调度系统中的作业名为test;
-p cpu # 作业提交的指定分区为cpu
-n 64 # 这个作业使用64核运行,如果程序不支持多线程(如openmp),这个数不应该超过1;
--error=%J.err # 脚本执行的错误输出将被保存在当%j.err文件下,%j表示作业号;
--output=%J.ou # 脚本执行的输出将被保存在当%j.out文件下,%j表示作业号;
除此之外,还有一些常见的参数:
--help # 显示帮助信息;
-D, --chdir=<directory> # 指定工作目录;
--get-user-env # 获取当前的环境变量;
--gres=<list> # 使用gpu这类资源,如申请两块gpu则--gres=gpu:2
-J, --job-name=<jobname> # 指定该作业的作业名;
--mail-type=<type> # 指定状态发生时,发送邮件通知,有效种类为(NONE, BEGIN, END, FAIL, REQUEUE, ALL);
--mail-user=<user> # 发送给指定邮箱;
-n, --ntasks=<number> # sbatch并不会执行任务,当需要申请相应的资源来运行脚本,默认情况下一个任务一个核心,--cpus-per-task参数可以修改该默认值;
-c, --cpus-per-task=<ncpus> # 每个任务所需要的核心数,默认为1;
--ntasks-per-node=<ntasks> # 每个节点的任务数,--ntasks参数的优先级高于该参数,如果使用--ntasks这个参数,那么将会变为每个节点最多运行的任务数;
-o, --output=<filename pattern> # 输出文件,作业脚本中的输出将会输出到该文件;
-p, --partition=<partition_names> # 将作业提交到对应分区;
-q, --qos=<qos> # 指定QOS;
-t, --time=<time> # 允许作业运行的最大时间,目前未名一号和生科一号为5天,教学一号为两天;
-w, --nodelist=<node name list> # 指定申请的节点;
-x, --exclude=<node name list> # 排除指定的节点;
接下来是一个GPU作业的例子,假设我们想要申请一块GPU卡,并通过指令nvidia-smi来查看申请到GPU卡的信息,那么可以这么编写作业脚本:
#!/bin/bash
#SBATCH -J test
#SBATCH -p gpu4
#SBATCH -n 4
#SBATCH --gres=gpu:1
#SBATCH --error=%J.err
#SBATCH --output=%J.out
nvidia-smi
#SBATCH --gres=gpu:1 # 每个节点上申请一块GPU卡
最后是一个跨节点多核心的例子,假设我们想用两个节点,每个节点40个核心来运行vasp,那么可以这么编写作业脚本:
#!/bin/bash
#SBATCH -J test
#SBATCH -p cpu
#SBATCH -N 2
#SBATCH --ntasks-per-node=40
#SBATCH --error=%J.err
#SBATCH --output=%J.out
# 导入MPI运行环境
module load intel/2017u5
# 导入VASP运行环境
module load vasp/5.4.4
# 执行VASP并行计算程序
mpirun -n 80 vasp_std
scontrol show job $SLURM_JOBID
2) salloc交互式运行作业
运行作业的第二种方式是通过salloc交互式运行作业,首先需要申请计算节点,然后登录到申请到的计算节点上运行指令。salloc的参数与sbatch相同,以下提供申请一个节点6个核心,并跳转到该节点上运行程序示例:
salloc -p cpu -N1 -n6
# salloc 申请成功后会返回申请到的节点和作业ID等信息,假设申请到的是cu01节点,作业ID为1078858
ssh cu01 # 直接登录到刚刚申请到的节点cu01调式作业
scancel 1078858 # 计算资源使用完后取消作业
squeue -j 1078858 # 查看作业是否还在运行,确保作业已经退出,避免产生不必要的费用
申请一个GPU节点,6个核心,1块GPU卡,并跳转到节点上运行程序;
salloc -p gpu4 -N1 -n6 --gres=gpu:4
# 假设申请成功后返回的作业号为1078858,申请到的节点是gpu05
ssh gpu05 # 登录到gpu05上调式作业
scancel 1078858 # 计算结束后结束任务
squeue -j 1078858 # 确保作业已经退出
最后介绍一个跨节点使用案例;
申请两个节点,每个节点12个核心
salloc -p cpu -N2 --ntasks-per-node=80
# salloc 申请成功后会返回申请到的节点和作业ID等信息,假设申请到的是a8u03n[05-06]节点,作业ID为1078858
# 这里申请两个节点,每个节点12个进程,每个进程一个核心
# 根据需求导入MPI环境
module load intel/2017u5
# 根据以下命令生成MPI需要的machine file
srun hostname -s | sort -n > slurm.hosts
mpirun -np 80 -machinefile slurm.hosts hostname
# 结束后退出或者结束任务
scancel 1078858
3) sinfo查看资源空闲状态
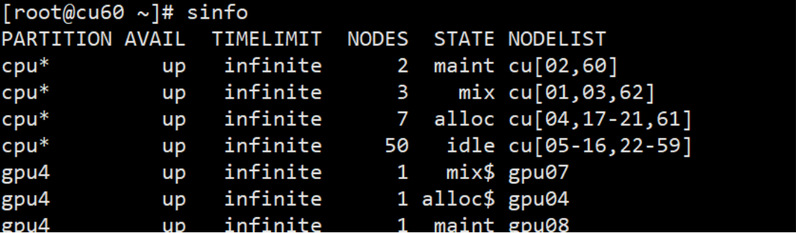
sinfo可查询各分区节点的空闲状态,输入sinfo命令,返回状态显示idel为空闲,mix为节点部分核心可以使用,alloc为已被占用,maint为维护中,如下所示:
-d # 查看集群中没有响应的节点;
-i <seconds> # 每隔相应的秒数,对输出的分区节点信息进行刷新
-n <name_list> # 显示指定节点的信息,如果指定多个节点的话用逗号隔开;
-N # 按每个节点一行的格式来显示信息;
-p # <partition> 显示指定分区的信息,如果指定多个分区的话用逗号隔开;
-r # 只显示响应的节点;
-R # 显示节点不正常工作的原因;
4) squeue/sq查看作业队列
用户可以通过squeue或sq命令查看提交作业的排队情况,如下所示输入sq命令:
sq
默认情况下squeue或sq输出的内容如下,分别是作业号,分区,作业名,用户,作业状态,运行时间,节点数量,运行节点(如果还在排队则显示排队原因)。
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
--help # 显示squeue命令的使用帮助信息;
-A <account_list> # 显示指定账户下所有用户的作业,如果是多个账户的话用逗号隔开;
-i <seconds> # 每隔相应的秒数,对输出的作业信息进行刷新
-j <job_id_list> #显示指定作业号作业信息,如果是多个作业号的话用逗号隔开;
-n <name_list> #显示指定节点上作业信息,如果指定多个节点的话用逗号隔开;
-t <state_list> # 显示指定状态的作业信息,如果指定多个状态的话用逗号隔开;
-u <user_list> # 显示指定用户的作业信息,如果是多个用户的话用逗号隔开;
-w <hostlist> # 显示指定节点上运行的作业,如果是多个节点的话用逗号隔开;
5) scancel取消作业
用户可以通过scancel命令取消账号中已提交的作业,如下所示:
# 取消作业ID为123的作业
scancel 123
# 注意whoami前后不是单引号
scancel -u user_name
--help # 显示scancel命令的使用帮助信息;
-A <account> # 取消指定账户的作业,如果没有指定job_id,将取消所有;
-n <job_name> # 取消指定作业名的作业;
-p <partition_name> # 取消指定分区的作业;
-q <qos> # 取消指定qos的作业;
-t <job_state_name> # 取消指定作态的作业,PENDING, RUNNING 或 SUSPENDED;
-u <user_name> # 取消指定用户下的作业;
